Killing a `Cow` made my JSON formatter 42% faster
Em dashes: 12
A formatter styles code consistently, usually improving human readability. If you are unfamiliar with formatters, tokenizers, or abstract syntax trees, see my article on how formatters work
The JavaScript ecosystem has a gap—most formatters are either featureful or fast. Prettier is the standard in the JavaScript ecosystem, but it’s not the fastest. Oxfmt has made major strides—supporting parity with Prettier’s JavaScript formatting with much improved performance. One report found a migration to Oxfmt formatted their repo 6.5x faster—from 13.9 seconds to 2.1
However these gains do not apply to JSON. Oxfmt is 10–20% slower than Prettier for JSON. Oxfmt has a native JavaScript formatter, but it reasonably delegates to Prettier for file types without native implementations1. Oxfmt plans for a native JSON implementation this year!
Prettier and Oxfmt both take more than a second to format a 2MB JSON file, while my formatter, JJPWRGEM takes around 30 milliseconds
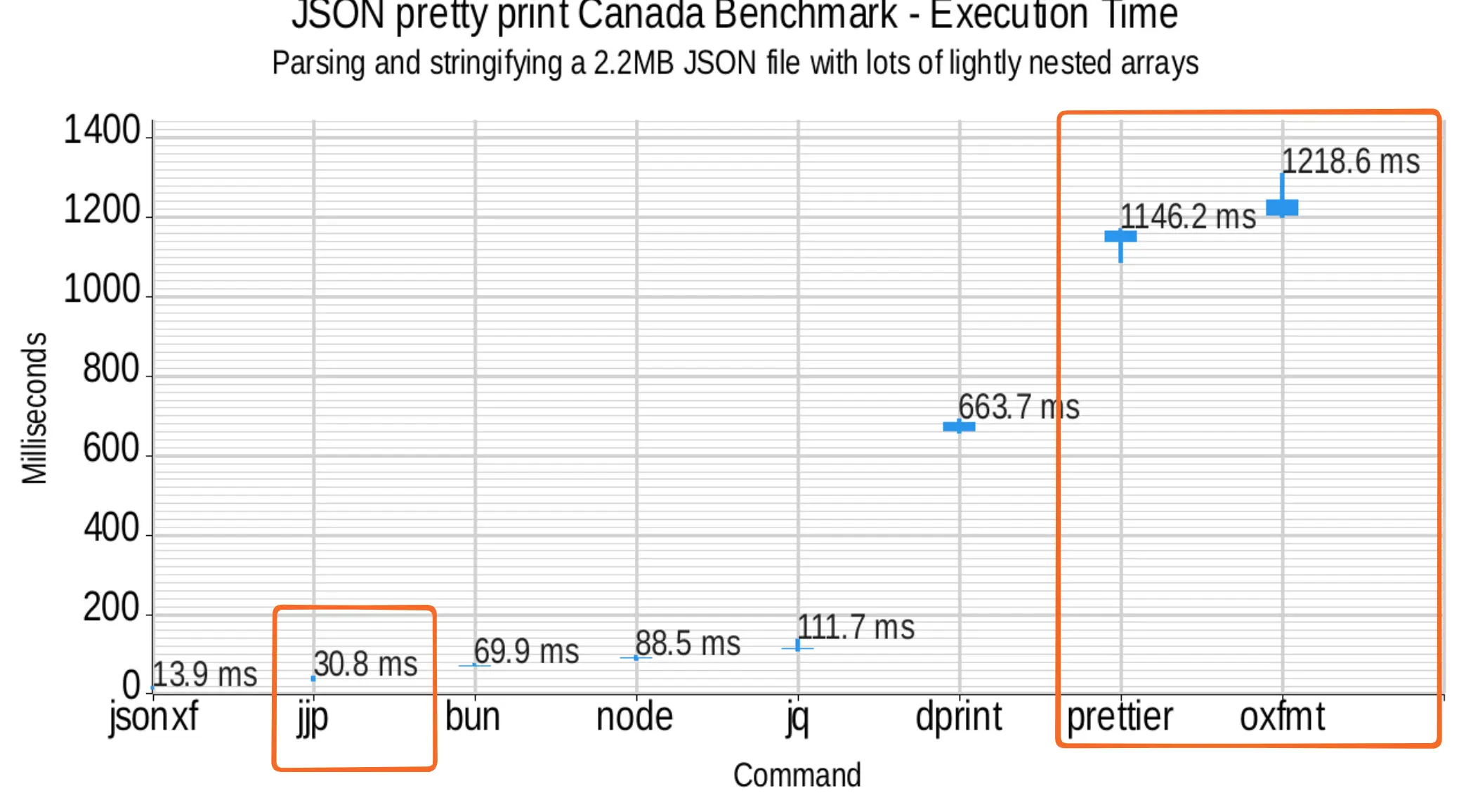
Dense floats benchmark - Execution time
Parsing and stringifying a 2.2MB JSON file with lots of lightly nested arrays
See the full benchmarks for more details
See tabular benchmarks
Command Median Time jsonxf 14.0ms jjp 31.0ms bun 70.0ms node 89.0ms jq 112.0ms dprint 665.0ms prettier 1149.0ms oxfmt 1218.0ms
To be fair, JJPWRGEM doesn’t have Prettier feature parity—but what if it did? It’s a great base, and I am confident there are performance gains to be found while implementing features
I started with a well scoped and impactful change—normalizing numbers like Prettier—and I ended up speeding up my formatter by 42% in the process. If you’re interested in how that was calculated, jump to the final benchmarks
Number normalization
Let’s start with 3 normalizations related to scientific notation for simplicity. They all build nicely on each other
- Lowercases exponent symbol (from
1E5to1e5) - Strips
+(from1e+5to1e5) - Removes 0 exponents (from
1e0to1)
Baseline
At the moment, JJPWRGEM leaves numbers untouched and represents them as a single Cow<str>. I’ll explain more about Cow as relevant
I am benchmarking against several files with varying data shapes. Here are a few samples
dense floats
{ "type": "FeatureCollection",
"features": [{
"type": "Feature",
"properties": { "name": "Canada" },
"geometry": {"type":"Polygon","coordinates":[
[[-65.613616999999977,43.420273000000009],
[-65.619720000000029,43.418052999999986],
[-65.625,43.421379000000059], ...]
]}
}]
}many objects and integers
{
"events": {
"138586341": {
"description": null,
"id": 138586341,
"name": "30th Anniversary Tour",
"subTopicIds": [337184269, 337184283],
"topicIds": [324846099, 107888604]
}
},
"areaNames": {
"205705993": "Arrière-scène central",
"205705994": "1er balcon central"
}
}strings and deep nesting
{
"statuses": [{
"metadata": { "result_type": "recent", "iso_language_code": "ja" },
"created_at": "Sun Aug 31 00:29:15 +0000 2014",
"id": 505874924095815700,
"text": "@aym0566x \n\n名前:前田あゆみ\n第...",
...
}]
}Deser refers to deserializing into an abstract syntax tree. The performance is represented by throughput to avoid size based discrepancies. A 1MB file will be formatter faster than a 3MB file, but MB/s is comparable for both!
| benchmark | baseline (MB/s) |
|---|---|
| deser/dense floats | 115.6 |
| deser/many objects and integers | 385.5 |
| deser/strings and deep nesting | 257.8 |
Iteration 0: Build a new normalized string
The simplest approach is to build new strings for improperly formatted numbers
Unfortunately, each number needs traversed twice, once to find the range and again to validate it. Even if there are no numbers in our input, it requires slow heap allocations
We need a more complex approach that takes references to chunks of the input string
Iteration 1: 2 Cows
Only 2 parts of each number matter. The mantissa to left of the e and the exponent to the right. You may recognize this as scientific notation—1e5 represents
Say we have 1E+5, we can store 1 and 5 and reconstruct 1e5. If we have an exponent, the e or E is lowercased. Any +s can be skipped since 1e5 and 1e+5 are equivalent
pub enum Token<'a> {
Number {
mantissa: Cow<'a, str>,
exponent: Cow<'a, str>
},
}This approach works, but lowers performance across the board. Cow<str> comes with overhead raw str avoids, negatively affecting datasets without many numbers
| benchmark | baseline (MB/s) | this (MB/s) | delta |
|---|---|---|---|
| deser/dense floats | 115.6 | 101.1 | -12.5% |
| deser/many objects and integers | 385.5 | 289.3 | -25.0% |
| deser/strings and deep nesting | 257.8 | 214.8 | -16.7% |
What is a Cow anyways?
Cow stands for Clone On Write. It references data until mutation is needed, then duplicates it. This pays off when most values are unchanged—only data needing modification is cloned
A to_lowercase function is a great use case—if the input is already lowercase, you can return a reference to the same string! In Rust terms, the data is “borrowed”
fn to_lowercase(string: &str) -> Cow<'_, str> {
if string.is_lowercase() {
// reference input string
Cow::Borrowed(string)
} else {
// make a new string
Cow::Owned(string.to_lowercase())
}
}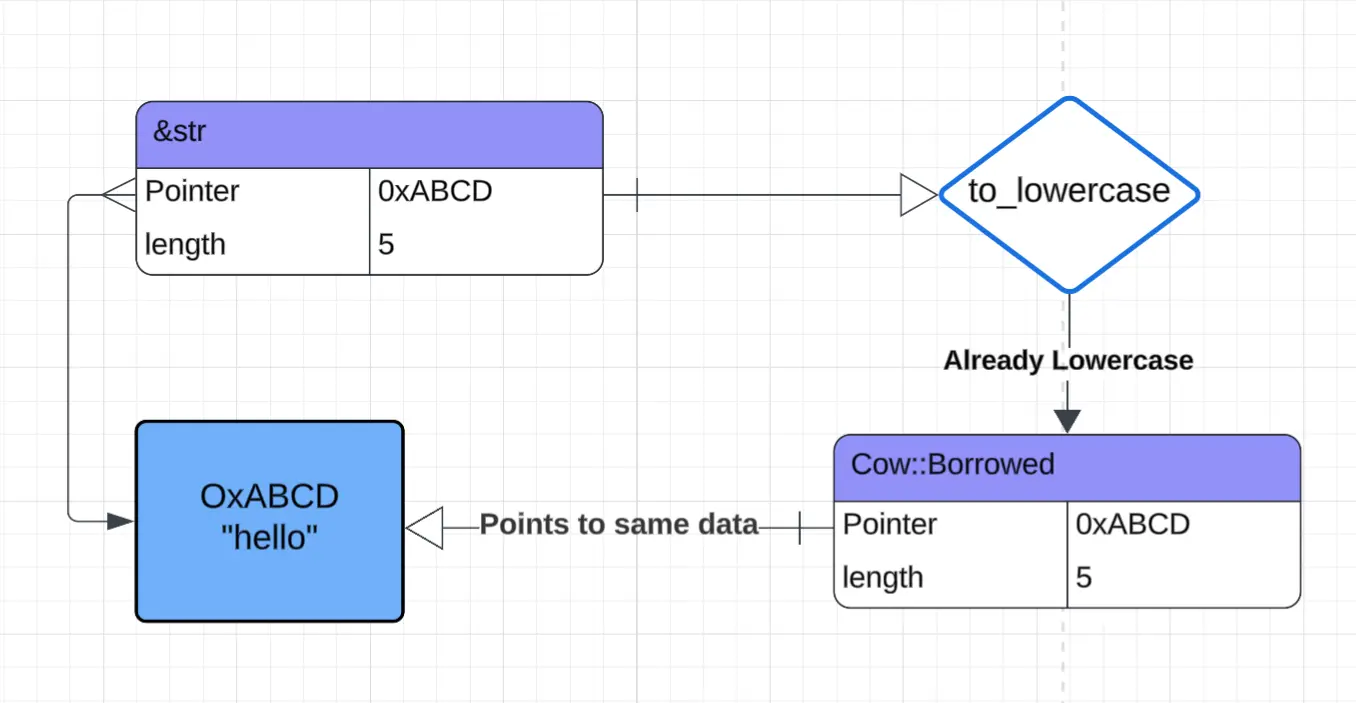
Diagram showing a call to
to_lowercasewith an already-lowercase&strreturns aCow::Borrowedpointing to the same memory, avoiding allocation
Now imagine an uppercase input. A new string is created to avoid changing the referenced string. The Cow “owns” the new data and can update the allocated capacity without reallocating, but it must clean up that data when it goes out of scope
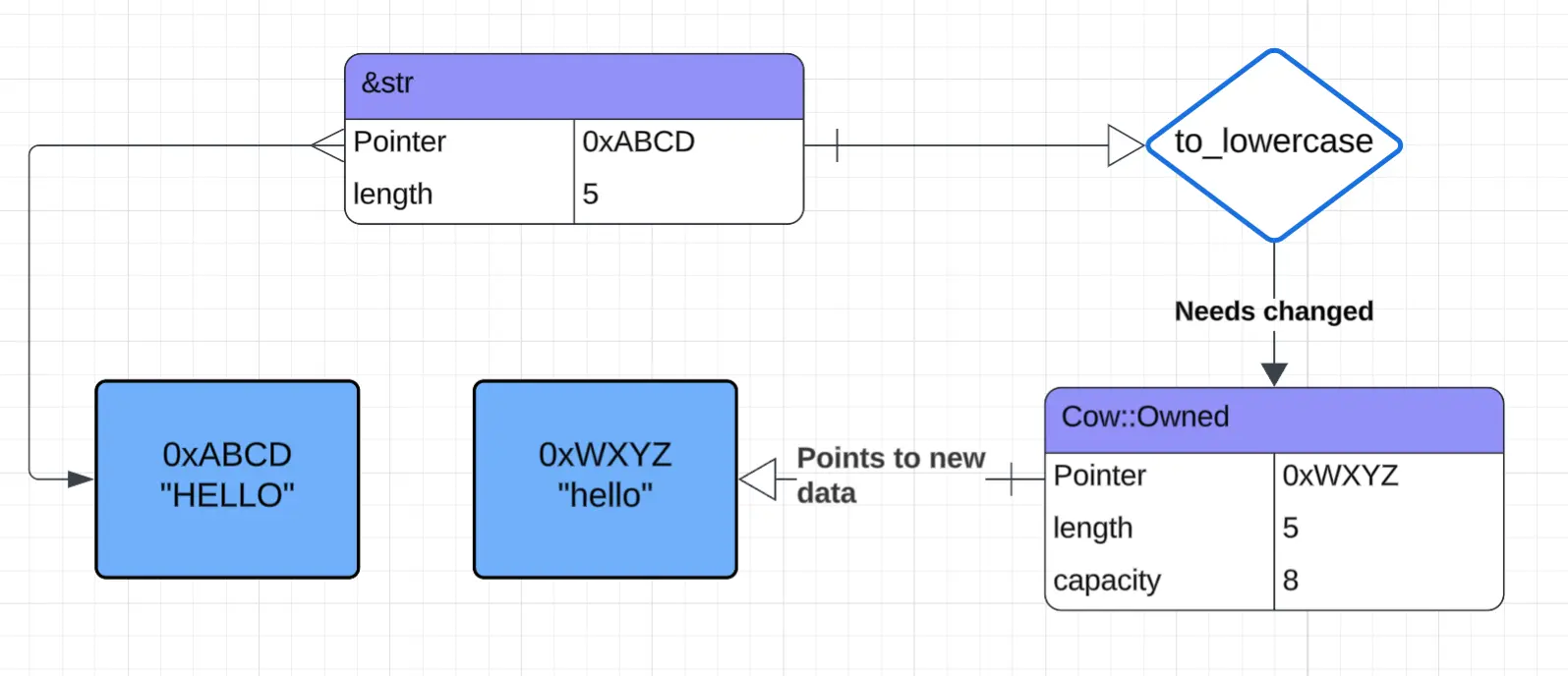
Diagram showing a call to
to_lowercasewith an uppercase&strreturns aCow::Ownedpointing to a new allocation
Since a Cow is potentially responsible to clean up its data, it pays a small performance penalty when it goes out of scope. This ultimately renders 20% of the program’s instructions useless! Cow’s flexibility was never used
Even worse, each Token could be a Number, so cleanup checks run on tokens like OpenCurlyBrace that carry no data
Let’s get rid of the Cows!
Iteration 2: use &str instead of Cow<str>
pub enum Token<'a> {
Number {
mantissa: &'a str,
exponent: &'a str
},
}The compiler gets to remove all those cleanup instructions and branches, which is a huge win for every datasets
However, the “dense floats” dataset is below baseline since it has no exponents—paying the cost to check for exponents that never materialize. Let’s try splitting the tokens in 2 to avoid paying that cost
| benchmark | baseline (MB/s) | this (MB/s) | delta |
|---|---|---|---|
| deser/dense floats | 115.6 | 111.0 | -3.9% |
| deser/many objects and integers | 385.6 | 442.9 | +14.9% |
| deser/strings and deep nesting | 258.7 | 341.4 | +32.0% |
Iteration 3: Separate Mantissa and Exponent variants
Instead of 1 variant holding the full number, we’ll split it in 2 so the CPU can read 2 tokens at once, saving an instruction
pub enum Token<'a> {
Mantissa(&'a str),
Exponent(&'a str),
}CPUs read memory in chunks—like reading a word at a time instead of a full sentence
A focused CPU thinking and reading one JSON Token at a time
A CPU fetches 64 bytes of RAM at a time into its cache for processing, meaning 2 &strs or Cow<str>s per token limits reads to one Token at a time
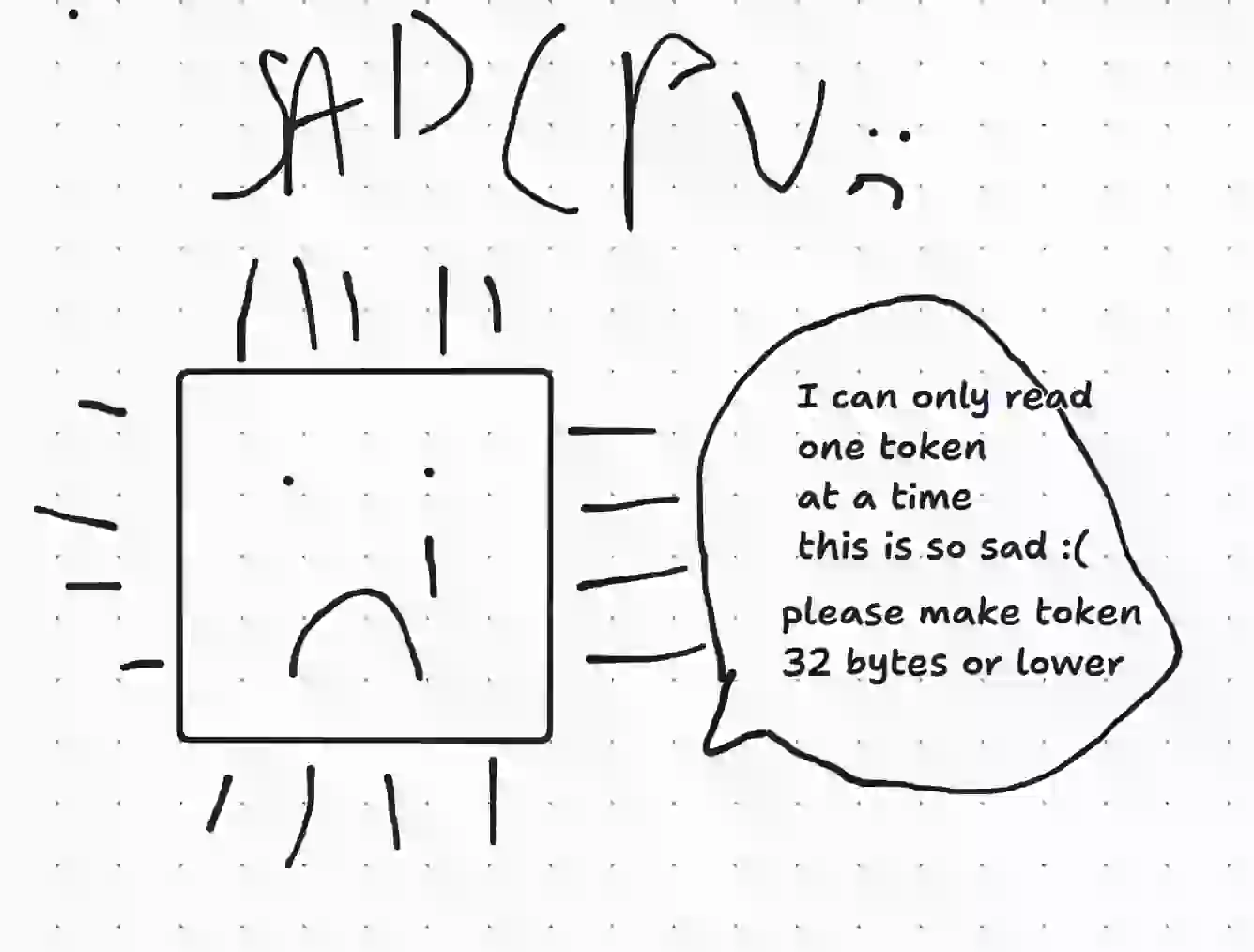
A sad CPU saying “I can only read one token at a time this is so sad. please make token 32 bytes or lower so I can read 2 at once”
Variants holding 1 &str or Cow<str> are both 24 bytes, so the 2 fit in 1 read

A happy CPU saying “I can read two tokens at a time since token is 24 bytes thank you so much, enjoy higher throughput”
“Dense floats” deserialization is now better than baseline, but “many objects and integers” has regressed from the previous iteration due to higher number parsing overhead
| benchmark | prev (MB/s) | this (MB/s) | delta |
|---|---|---|---|
| deser/dense floats | 111.0 | 122.6 | +10.5% |
| deser/many objects and integers | 442.9 | 401.7 | -9.3% |
| deser/strings and deep nesting | 341.4 | 356.8 | +4.5% |
Iteration 4: Split the state machine
Parsing both the mantissa and exponent has ballooned the number state machine to 88 bytes. Just like with larger tokens, The CPU needs two reads per state change
A state machine is like a sequential checklist. To find where a number starts and ends, we can follow this (abbreviated) checklist
- start with a digit or minus sign
- then another digit or a
.for a float - …
- finish
At first, it made sense to have a full number state machine, but now we care about 2 separate chunks of that number
Not only will splitting allow the CPU to fetch the full state in one read, the compiler better optimize with less possibilities to reason about
enum MantissaState { ... }
enum ExponentState {
MinusOrPlusOrDigit,
AfterSign,
Digits,
Zero,
End
}Now the “many objects and integers” dataset is even faster than baseline!
Unfortunately, “dense floats” has regressed to slightly below baseline, but that’s an acceptable tradeoff since typical JSON has more mixed data
| benchmark | prev (MB/s) | this (MB/s) | delta |
|---|---|---|---|
| deser/dense floats | 122.6 | 111.3 | -9.2% |
| deser/many objects and integers | 401.7 | 456.9 | +13.7% |
| deser/strings and deep nesting | 356.8 | 385.1 | +7.9% |
Final Benchmarks
Switching from Cow to str and splitting Number token and state machines both help to improve performance
The headline of “42%” improvement refers to the strings and deep nesting dataset deserialization + prettification. The slower stage will pull down the faster one, so we add their times together and covert back to MB/s
For the baseline case
For the new implementation
Resulting in a gain of around 42%
Deserialization into AST
Benchmarks converting a string into an AST
“dense floats” pays for the extra unused token per number, but “many objects and integers” and “strings and deep nesting” have massive improvements due to converting Cow to str
| baseline (MB/s) | new (MB/s) | delta | |
|---|---|---|---|
| dense floats | 115.6 | 111.3 | -3.7% |
| many objects and integers | 385.5 | 456.9 | +18.5% |
| strings and deep nesting | 257.8 | 385.1 | +49.4% |
Prettify from AST
Benchmarks serializing AST into a human readable string
“dense floats” suffered the most for a branch on each Number to check if an exponent is available to print. Other datasets are flat
| baseline (MB/s) | new (MB/s) | delta | |
|---|---|---|---|
| dense floats | 1424.7 | 1332.0 | -6.5% |
| many objects and integers | 1853.2 | 1845.3 | -0.4% |
| strings and deep nesting | 2091.1 | 2105.0 | +0.7% |
Uglify from Token Stream
Converts a string into tokens and serializes into a compact string
Big improvements across the board. Avoids building a syntax tree, so serialization avoids branching with formatting like with AST to string paths
| baseline (MB/s) | new (MB/s) | delta | |
|---|---|---|---|
| dense floats | 198.9 | 251.2 | +26.3% |
| many objects and integers | 449.8 | 630.4 | +40.2% |
| strings and deep nesting | 269.9 | 418.2 | +54.9% |
The benchmarks prove formatters can be fast and featureful—I did more work and improved performance in most categories. I’ll see y’all again when I implement the next Prettier feature!
Please consider subscribing to my RSS feed or your programs will give your CPU depression
A capacitor giving a CPU therapy. They say “So I hear you’ve been feeling cache miss-erable recently…”
The CPU is laying down on a coach and the capacitor is wearing glasses and holding a clipboard
Footnotes
-
I love everything Oxfmt has done so far, so this is not meant to put down Oxfmt. It’s the only Prettier compatible tooling I’ve found that doesn’t crash when formatting larger JSON files. I’ve seen some amazing architectural decisions they’ve made. Open source is a lot of work ↩